据国外媒体报道,在OpenAI联合创始人兼首席科学家伊尔亚·苏茨克维(Ilya Sutskever)和超级对齐小组联合负责人扬·雷科(Jan Leike)相继于本周离职之后,该公司负责研究未来超级智能模型安全性问题的超级对齐团队已经宣告解散。该团队的成员们面临了两种选择:离职或加入其他团队。
OpenAI于去年7月成立了超级对齐团队,由苏茨克维和雷科共同领导,旨在4年的时间内解决一个核心问题:如何确保超级智能的人工智能系统实现价值对齐与安全。当时,OpenAI曾明确表示,该团队将获得公司20%的算力资源。然而,随着多名研究人员在此前的离职,以及苏茨克维和雷科于本周的相继离开,OpenAI在周五确认了超级对齐团队的工作将被整合入公司其他研究部门。这一变化标志着超级对齐团队作为一个独立实体的结束,同时也预示着OpenAI在人工智能安全与价值对齐领域的研究方向和策略可能面临调整。
苏茨克维本周的离职引发了广泛的讨论。他本人不仅在2015年协助公司首席执行官山姆·奥特曼(Sam Altman)共同创立了OpenAI,还为ChatGPT的研究指明了方向。然而,他也是去年11月导致奥特曼被解雇的四名董事会成员之一。在随后的五天内,OpenAI经历了一场剧烈的内部纷争,最终奥特曼得以重返公司并恢复原职。在奥特曼被免职期间,OpenAI的员工发起了一场大规模抗议活动,最终促成了一项协议,根据该协议,苏茨克维和其他两名董事离开了董事会。
研究人员相继离职
在苏茨克维本周二宣布离开OpenAI的消息发布数小时后,超级对齐团队的另一位联合负责人雷科也在社交媒体平台X上透露了自己辞职的消息。苏茨克维并未详细解释其离职的原因,但他在X上表示:“OpenAI的发展轨迹令人赞叹,我坚信公司在现任领导团队的带领下,将能够构建一个既安全又有益的通用人工智能。”
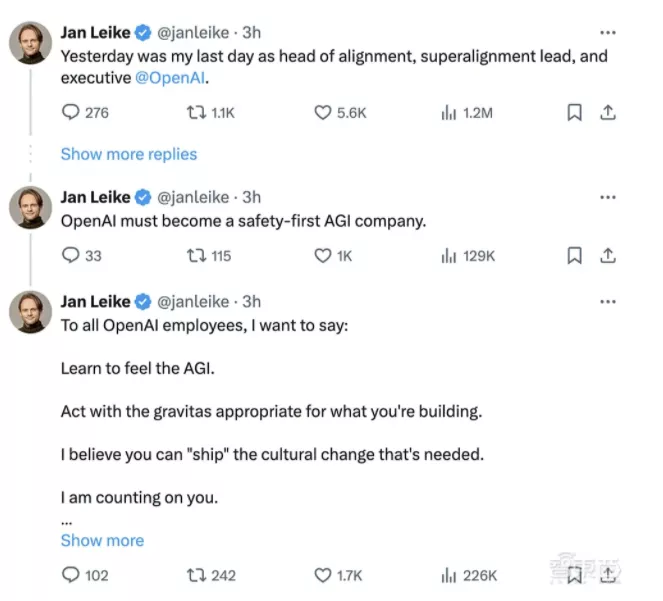
雷科则在X上详细阐述了他离职的原因,他指出:“我与OpenAI领导层在公司核心优先事项上的分歧已经持续了一段时间,直至我们达到了一个临界点。在过去几个月中,我的团队一直在逆风中前行。我们有时为了获取计算资源而挣扎,完成这项至关重要的研究变得越来越困难。”他还表示:“我认为我们应该投入更多的带宽来为下一代模型做好准备。在安全性、监控、准备、对抗鲁棒性、(超级)对齐、保密、社会影响等相关主题上。这些问题很难做好,我担心我们没有走上正确的轨道。”

这似乎是OpenAI高管首次公开表达公司将产品置于安全之上的观点。对此,奥特曼回应称:“我对雷科为OpenAI的对齐研究和安全文化所做的贡献表示深深的感激。他的离开让我感到非常难过。他所说的我们还有很多事情要做是正确的;我们致力于继续前进。
超级对齐团队的解散进一步证实了公司在去年11月治理危机之后内部的动荡。据外媒上个月报道,超级对齐团队的两名研究人员奥波德·阿申布伦纳(Leopold Aschenbrenner)和帕维尔·伊兹迈洛夫(Pavel Izmailov)因泄露公司机密而被解雇。团队的另一名成员威廉·桑德斯(William Saunders),根据以他的名字发布的互联网论坛帖子显示,于2月份离开了OpenAI。
此外,两位从事人工智能政策和治理研究的OpenAI研究员似乎也已离开公司。根据LinkedIn信息,库伦·奥基夫(Cullen O'Keefe)在4月份离开了他在政策前沿研究领域的领导职位。而共同撰写过多篇关于高级人工智能模型潜在危险的论文的研究员丹尼尔·科科塔伊洛(Daniel Kokotajlo),因对公司在人工通用智能时代能否负责任地行事失去信心,也已离开OpenAI。目前,这些显然已经离职的研究员都没有对评论请求做出回应。
OpenAI对苏茨克维或其他超级对齐团队成员的离职,以及对未来长期人工智能风险研究的问题均未发表评论。现在,由约翰·舒尔曼领导的团队将负责与更强大的模型相关的风险研究,他与他人共同领导着一个团队,负责在训练后微调人工智能模型。
尽管超级对齐团队并非唯一思考如何控制人工智能的团队,但其公开定位为致力于解决这一远景问题的主力团队。OpenAI在去年夏天宣布成立超级对齐团队时指出:“目前,我们还没有一种解决方案来指导或控制一个潜在的超级人工智能,阻止它变得不可控制。”
OpenAI的章程规定,公司必须安全地开发所谓的人工通用智能,或与人类相媲美或超越人类的技术,安全地并为人类的利益服务。苏茨克维和其他领导者经常强调谨慎行事的必要性。然而,OpenAI也是最早开发并向公众发布实验性人工智能项目的机构之一。
苏茨克维和雷科的离职发生在OpenAI最新产品发布会之后—该公司本周一刚推出了GPT-4o“多模态”模型,它使ChatGPT能够看到世界并以更自然、更人性化的方式进行对话。尽管没有迹象表明最近的离职与OpenAI开发更人性化人工智能或推出产品的努力有任何关系,但最新的进展确实引发了围绕隐私、情感操纵和网络安全风险的伦理问题。OpenAI还维护着另一个名为“准备就绪团队”的研究小组,专注于这些问题。
对奥特曼感到失望
如果一直在社交媒体X上关注OpenAI的“宫斗”闹剧,就可能会认为OpenAI秘密取得了巨大的技术突破。“伊尔亚发现了什么?”这个梗推测苏茨克维离职是因为他看到了一些可怕的东西,比如一个能够摧毁人类的人工智能系统。
但真正的答案可能与对技术的悲观无关,而更多地与对人类的悲观有关——尤其是对一个人:山姆·奥特曼。知情人士透露,以安全为重的超级对齐团队成员对奥特曼失去了信心。“这是一个信任逐渐崩溃的过程,就像多米诺骨牌一个接一个倒下,”知情人士透露。没有多少员工愿意公开谈论这件事。部分原因是OpenAI让员工在离职时签署包含不诋毁条款的离职协议。如果拒绝签署,员工将放弃在公司的股份,意味着可能会失去数百万美元。
不过也有例外,的确有员工在离职时没有签署协议,仍可以自由地批评OpenAI。在2022年加入OpenAI的科科塔伊洛,曾希望引导公司朝着安全部署人工智能的方向发展。他表示:“OpenAI正在训练越来越强大的人工智能系统,目标是最终在各个领域超越人类智能。如果处理得当,这可能是对人类最好的事情,但如果我们不小心,也可能是最糟糕的。”
OpenAI表示它想要构建人工通用智能,这是一个假设性的系统,可以在许多领域以人类或超人的水平执行。“我加入时抱有极大的希望,希望OpenAI能够崛起,在接近实现通用人工智能时表现得更加负责任。但对我们许多人来说,这逐渐变得清晰,这是不会发生的,”科科塔伊洛告诉我。“我逐渐对OpenAI领导层及其负责任地处理通用人工智能的能力失去了信任,所以我辞职了。”
自从“宫斗”事件以来,苏茨克维大约半年时间没有出现在OpenAI办公室——他一直远程共同领导超级对齐团队。虽然该团队有着远大的抱负,但它与奥特曼领导下的OpenAI日常运营脱节。奥特曼对被解雇的反应揭示了他的性格:他威胁要带走OpenAI全部员工,除非董事会重新聘用他;回归后坚持用对他有利的新成员填补董事会,显示出他决心抓住权力并避免未来的制约。OpenAI前同事和员工站出来描述他是一个操纵者,说话两面三刀——例如,他声称他想要优先考虑安全,但在行为上却与之矛盾。
举例来说,奥特曼正在与沙特阿拉伯等国商谈,这样他就可以创办一家新的人工智能芯片制造公司,为他提供构建尖端人工智能所需的大量资源。这令注重安全的员工感到震惊。如果奥特曼真的关心以最安全的方式构建和部署人工智能,为什么他似乎急于积累尽可能多的芯片,这只会增加技术的速度?同样,他为什么要承担与可能使用人工智能来加强数字监控或侵犯人权的政权合作的安全风险?
对员工来说,所有这些都导致了逐渐“失去信念,”一位了解公司的内部表示。


















{kind=link}